Index
PhD Takeaways
General Takeaways
- Communication
- The Race to Publish
- Why Research?
- Unintended Outcomes
- Following the Crowd
- Hammers w/out Nails
- Perfection is the Enemy of Progress
- Hard Problems vs Simple Problems
- Effort
- Academia vs Industry
A “Probabilistic” Model of Research
Research is a complicated process. It can be overwhelming because it’s not clear what being a good researcher even means! What does doing good work mean?. There is also a lot of advice floating around – where does this advice come from? Is there a model from which most advice emanates? How can one systematically reason about the process?
This document proposes one possible way to decompose research ideas into a simple model, and uses it as a framing device to comment on research and ideas. Its purpose is to show this decomposition process as a tool. Other than the model, you can read the sections in any order.
Thanks to the following for their feedback on earlier versions: sellam, yifan, marcua, aditya, jaan, gu, vijay, jmh.
If you have ideas of how to improve this document, please submit a pull request or issue, or find me on Twitter.
A Thinking Tool, Not a Recipe
This document is not a set of step-by-step instructions of how to “succeed” at research. Instead, it is a model for how to think about what success means, and how to judge ideas in a systematic way.
Part of the reason research is fun is because ideas and solutions can come from anywhere. It can come during postmortems of previous projects, thinking about what the future could be, being confused about why the world works in a weird way, by deeply studying multiple research areas and finding a connection, or more! Here is a short list of articles that describe the genesis of some ideas:
- Vijay’s CSR Tales project documents the background behind research projects and is worth reading.
- Philip Guo writes Inception: the moment when a new research project is born
- Some discussion in marcua’s N=1 Guide to the PhD
- Some more discussion in the N=2 Guide to the PhD
The Model
Let’s start by considering the notion of $Impact$ for a unit of research, meaning the amount that the world changes if a given unit of research is performed. This is a deliberately vague notion, because $Impact$ is based on your own value system and what you consider important. This could be happiness, or money, or changing how people think, or anything else.
We will quantify it as the sum of all possible outcomes, described below. Further, for simplicity, let’s assume a paper is the unit of research, and we would like to estimate its affect on Impact.
Outcomes
We can imagine a possible outcome $o$, which could represent a product, another project, social change; its value could measure profits, social equality, happiness, etc. Producing a paper changes how likely a given outcome will happen. In marketing, this is called lift, which means how much a treatment (producing the paper) differs from the control. In our case, we simplify the control to be not accounting for the paper at all:
\[P(o | paper) - P(o)\]If we were to sum over all possible outcomes $\mathbb{O}$, it would represent the likely outcome value assuming the paper is successfully produced. This is basically the expected Outcome, where $1$ means the best possible expected outcome, and $0$ means the worst possible:
\[\begin{align} E[Outcome|paper] =& \sum_{o_i\in\mathbb{O}} o_i \times P(o_i | paper) - P(o_i)\\ =& \left(\sum_{o_i\in\mathbb{O}} o_i \times P(o_i | paper)\right) - \cancelto{0}{P(\mathbb{O})} \end{align}\]For the purposes of this discussion, we will ignore the control term $P(\mathbb{O})$ by setting it to $0$, but keep in mind that it embodies concepts such as related work and how industry will naturally progress. If interested, I encourage you to further model this component and explore its implications!
Papers
But what does it take to produce a paper? There are really three elements:
- Hypothesis: what is being claimed and what evidence does the paper assert is sufficient to prove the claim? This is often called experimental design. High quality design means that collecting the evidence is sufficient to prove/disprove the claim. Low quality design means that even collecting the evidence isn’t enough and there’s a gap in the logic. Let $1$ be if it is trivial to collect sufficient evidence to prove the claim (e.g., humans exist), and $0$ mean that it is pretty much impossible to prove the claim (e.g., it is possible to move faster than light).
A theory paper claims that a theorem is true, and provides evidence in the form of a (correct) proof. A systems paper claims that a new system designs can make a particular system “better” than existing designs, and provides evidence in the form of code, benchmarks, and design descriptions..
-
Evidence: are you, fellow researcher, capable of collecting the evidence necessary to uphold the claim? Let $1$ mean you have the skills, the resources, and the capability to collect the evidence, and let $0$ mean that you are certainly not able to collect the evidence.
-
Assumptions: the vast majority of claims are not universally valid, and require that some set of assumptions be true. Let $1$ mean that the necessary assumptions hold, and $0$ means that it is not possible to satisfy the assumptions.
You can think of each of these terms as probabilities, in which case the probability that the paper is successfully produced would be:
\[P(paper) = P(hypothesis) \times P(evidence) \times P(assumptions)\]Putting it Together
We can now talk about the expected Impact of a paper based on the possible outcomes and the likelihood of the paper!
\[\begin{align} E[Impact | paper] = &P(paper) \times E[Outcome | paper]\\ = &P(hypothesis) \times P(evidence) \times \\ &P(assumptions) \times E[Outcome | paper] \end{align}\]If we simplify the notation, we end up with $Impact$ being composed of four parts:
\[Impact = Hypothesis\times Evidence\times Assumptions\times Outcome\]We will use the following diagram throughout this document to illustrate concepts. Here, each term is $1$, so the impact is $1$:
However, if any term is lower, then the inner bar will be shorter. For instance, if the assumptions are unlikely and the experimental design (hypothesis) is shakey, then:
The specific values of each term is less important than which terms are the focus of attention, and will maximize $Impact$.
Research as Optimization
Recall that $Impact$ is computed over all possible outcomes that could be affected by the paper. In reality, we are mere mortals, could not possibly imagine all of these outcomes, and may have optimistically imagined outcomes that actually would not come true. Instead, we have a limited view of possible outcomes, and we can call that $\mathbb{O}_{limited}$.
We can think of all research decisions from the perspective of the following optimization problem:
maximizes expected impact $E[Impact | paper^*]$
This formulation can be helpful because we can borrow from existing work such as estimation theory, (non)convex optimization, probability theory, etc. It also makes clear that we are optimizing under partial, often biased, information ($\mathbb{O}_{limited}$).
Takeaways
There are many takeaways that we can make based studying the above optimization problem. I group them into “things related to the PhD”, and “things in general”.
PhD Takeaways
PhD as Certification
The PhD is not magical. You can think of it as certifying that you have sufficient knowledge to conduct research. In other words, given $Paper$ and $Assumption$, you can design a reasonably good experiment and collect adequate evidence. Notice they don’t need to be perfect, just above some threshold. The greyed out terms don’t matter for certification.
These are the “mechanical” parts of conducting research, and is primarily about making sure that you can do things correctly. An important purpose of taking courses, coding, doing internships, mentorship, reading papers, receiving criticism is to improve this aspect.
Ideas, Novelty, Vision
Assuming you’re “certified”, researchers primarily differ based on taste (e.g., what a good outcome means to you). This boils down to the quality of the ideas, and the researcher’s vision.
Ideas: identifying great outcomes
- One example is to identify an exceptionally great outcome (e.g., replacing transistors) that goes beyond what is currently possible
Vision: can you anticipate the future?
- One aspect is to anticipating the future by identifying assumptions that are currently not true ($\approx 0$), but will likely be true in the future. Companies like Gartner try to do this for you, but as researchers at the cutting edge, perhaps you can see a bit further.
- Another aspect is the ability to consider more outcomes (a larger $|\mathbb{O}_{limited}|$ in our optimization problem)
It is important to note that identifyng great outcomes, and predicting the future are difficult. There can be a lot of uncertainty and lack of confidence in younger researchers, and it is important for the advisor and community to nurture these skills.
Applying for a PhD
It is clear that one hopes to admit graduate students that have the capacity to work on research that have high expected impact. Faculty reviewers naturally seek to estimate each of the model terms from the application and interviews.
The quantifiable ones that are easier to measure are also what the PhD certifies: $Hypothesis$ and $Evidence$. If you have done past research or complex projects, they can be used to demonstrate technical competence. This simply means it is more likely that you can learn and complete projects of interest. This doesn’t mean you need to know everything - that’s the purpose of taking relevant classes, working on starter research projects, and interning. If you assume that faculty are risk adverse, they will look for students with more samples, or samples that have high certainty described in recommendation letters.
The intangible components are related to ideas and vision. This is part of the value of the essay. It is harder to illustrate this unless you have led projects in the past. If this is the case, describe the positive outcomes enabled by your work! Show that you have vision by remarking about ways to solve our optimization problem.
Personally, once I am convinced that an applicant is capable of learning the technical components of whatever a set of research directions might need, I soley focus on the Vision and Ideas components of the model. These could be illustrated, but are not limited to, the following:
- $Assumptions$ that may change in the future
- Outcomes that people are not thinking about ($\mathbb{O}_{limited}$)
- Techniques that people are not thinking of that could dramatically boost the ability to gather $Evidence$
Reviewing and Reading Papers
You will read and present many papers throughout your PhD. Eventually you will have the opportunity to review papers. The two activites overlap a lot, so I’ll mainly describe this subsection in terms of paper reviewing.
Reviewing is checking that $E[Impact|Paper]$ is high enough for the paper, with a correctness constraint. It’s important that published papers satisfy $Hypothesis\times Evidence\approx 1$. It would be embarassing to you and the community if factually inaccurate papers slip through the cracks. You are also checking that the assumptions actually hold ($Assumption > 0$). These can take time but is “mechanical”.
The hard part is evaluating that the paper’s ideas could have desirable outcomes so that its impact is above some threshold $\tau$:
\[E[Impact|Paper] > \tau\]The threshold $\tau$ is ill defined, but generally “higher-tier” venues have a higher threshold than lower tier venues. Since it is ill-defined, a common reason to reject a paper is that the paper lacks “originality” or the “contribution is too small”. This can be because the $Outcomes$ are not clearly spelled out, or the connection between the paper’s ideas and the outcomes are unclear ($P(o|Paper) = ?$)
This is where it’s important to stop yourself from viewing the submission from an adversarial perspective! If you could imagine positive outcomes that fall out from the paper, even if the authors missed them, then the paper could be worth accepting! Recall from above that ideas are to be nutured by the PhD process and the research community. Otherwise, we risk holding our field back.
3 Types of Papers
Since the ultimate goal is to identify papers that could maximize $E[Impact|Paper]$, let’s look at how that affects different types of papers. I’ll base this on topics I am aquainted with:
Improving a well established problem, and why the experimental bar is higher:
Consider a paper that proposes a system design for a super fast key-value system. The value of a faster system is well established, meaning there is an agreed upon set of outcomes. It is also clear the types of evidence (xacts per second, concurrency, etc) needed to illustrate the paper’s claims. Thus the main items to scrutinize are the techniques to establish $Evidence$ and the system’s $Assumption$. For instance, if it only works for single note transactions, or read only workloads, then it lowers the $Assumption$ term. Since most terms are fixed, it naturally leads to emphasis on system design, assumptions, and evaluation.
The Vision(ary) paper highlights a set of outcomes so different from the rest of the research community that it’s worth getting the word out because there’s potential to increase $E[Impact]$ of the whole community.
By 2011, Mechanical Turk (MTurk) had been around for about 6 years, often for labeling and data cleaning/collection tasks, and was getting attention from HCI communities. Adam Marcus suggested that MTurk was at a price point where workers could be thought of as databases themselves. Despite lots of work on modeling sensors, the web, remote machines, and files as databases, thinking through the implications of fleshy, human databases was pretty exciting and we wrote a “vision paper” around the idea. It sketched an architecture and slapped together a language (mediocre $Evidence$), made hand-wavy $Assumption$, but focused on the potential of great outcomes by citing existing human-intensive markets such as transcription, which was a multi-billion dollar industry.
The “Perfect” paper scores high on every term in our model. These tend to win “test of time” awards later on, because most people can’t predict how $Outcomes$ will actually play out.
Provenance is the idea of tracking the input records/objects that contributed to a result. There were many definitions of what “contribute” means, and different ways of modeling provenance. The Provenance Semirings paper introduced the notion of representing the provenance of an output record $y$ as semiring polynomials over input records. Basically, $y=x_1 + 2x_2$ means that $x_1$ and two copies of $x_2$ were used to derive the output $y$. They showed correctness for an important subset of SQL, and showed existing notions of “contribution” were special cases. It also presented a universe of mathematical tools to think about provenance, and immediately impacted any application that relies on provenance (e.g., auditing, derivation tracking, incremental view deletion).
The paper proved correctness, so $Hypothesis=1$. The assumptions were simply that you cared about provenance, and there was already a set of important applications that relied on provenance. It felt like the number of outcomes would only increase with time. In effect, every term in our model was high.
Other technologies such as transistors, CRISPR, and fundamental science can fall into this category.
Least Publishable Units
There is a subclass of paper widely considered as Least Publishable Units (LPUs). These are technically correct, but not really meaningful. In other words, some combination of the terms are so low that the impact is approximately $0$. For instance:
- The problem is made up, so $Assumption \approx 0$
- There likely doesn’t exist any positive outcomes, so $Outcome\approx 0$
My first “solo” author paper has elements of an LPU.
Shinobi was a database data-layout optimization tool. The idea is that indexes are useful for reading small amounts of data, but can slow down insert operations since the indexes need to be updated. Instead, it would partition the data in the table and dynamically add indexes for read-heavy partitions, and drop indexes if partitions became insert heavy. However, it only worked for geo-spatial data (e.g., checkins, car locations) and if access patterns were very predictable. Even though it beat baselines, it was kind of slow in absolute terms.
HOWEVER! It was important to write the paper as a training exercise for problem selection and developing skills so that I could collect evidence for harder problems in the future.
General Comments
In this section, we interpret many aspects of research in terms of maximizing $E[Impact|Paper]$. We assume that you have a PhD certificate, meaning $Hypothesis\times Evidence \approx 1$.
Communication
There is a commonly held ideal to “let the work speak for itself”, meaning that good work will be recognized and appreciated. It implicitly discourages communication if the measure of impact is fame. But what if we care about impact in terms of changing society, policy, lives, or even other researchers’ habits and tools?
That would mean that an outcome $o$ that we want is for some other researcher to have greater impact by using our ideas. For this to happen, the other researcher has to both read and understand our paper:
\[o \approx E[Impact | Other]\times P(Understands\ Paper)\times P(Reads\ Paper)\]- $P(Reads\ Paper)$. The researcher must be aware of the work! With arXiV and larger and larger conferences, it is difficult for any researcher to read everything. Thus, she must be convinced to read our paper. Let’s call this marketing, explored below.
- $P(Understands\ Paper)$. The researcher has been convinced to read your paper! Will it be easy for her to figure out what your paper is saying? This is about writing clearly, thoroughly, and unambiguously, so that she can take your ideas and techniques and actually use them. This is also why examples are important to illustrate applications of your techniques/ideas.
For related reading, see Diffusion of Innovations
Marketing
Let’s look into $P(Reads\ Paper)$, which is proportional to the amount of marketing. Marketing is somewhat of sensitive issue in academia, but worth talking about. We can break it into two terms:
\[P(Reads\ Paper) \propto Marketing = P(Awareness)\times P(Convinced)\]- $P(Awareness)$ can be called “Amount of Marketing”. This includes giving talks, writing blog posts, making tweets, posting videos, talking to journalists.
- $P(Convinced)$ can be called “Quality of Marketing”. This is whether or not the quality of the marketing is good enough that prospective researcher considers it worthwhile. In general, this term should be $\approx 1$. This is why it can easily take a month or more to create a conference talk.
Viewing “marketing” through an optimization lens helps us think about two common types of sub-optimal strategies (since $P(Convinced)\approx1$):
- $Marketing\gg E[Impact]$ Overmarketing is when the amount of awareness is not commensurate with the expected impact of the work on others.
- $Marketing\ll E[impact]$ Arguably a more wide-spread issue is undermarketing, where work that could have lots of impact is not marketed enough for people to know about it.
Both are suboptimal because it misleads others (the first case), or deprives others from doing impactful work (the second case). The first case is a waste of resources, and it is easy to focus on the potential outcomes rather than the limitations in the assumptions and what the evidence can actually imply.
I think the latter case is a bigger issue because it directly reduces the impact of the paper, since people will simply not know about it. Also, the latter is more widespread and can be ameliorated via training. Why are papers undermarketed? My hypothesis is that $E[Impact|Paper]$ is difficult to measure, and the authors are overly conservative in their estimates. Meaning that the author’s perception of their own work is lower than what it actually is. Since our terms are probabilities, consider applying your favorite estimation procedure; for instance, sampling from colleagues is a good way of compensating for your internal bias.
Beyond maintaining a homepage (and lab website after starting at Columbia), I have traditionally undermarketed my work for the same reasons as above: I was not confident whether or not my work mattered. At Columbia, I promoted my mentees’ work, because they deserved it, but otherwise did not do much.
I took a teaching break Fall 2017, and I forced myself to give a series of talks at friendly universities and companies. The feedback about our research direction was overwhelmingly kind, positive, and constructive. That boost of confidence has spurred me to more actively promote my lab, and was the impetus for this document.
I think the lesson is to talk often and talk widely about your work with colleagues you respect.
The Race to Publish
Often, it can feel like there is a race to be the first to publish before every other research group. This makes the entire research enterprise feel like a competition, and a zero sum game. You could also argue that a currently hot area is where there will be impact, but the model suggests that it is not the only case.
It is easy to extend our model to take into account other researchers working on the same problem. We can assume that every term ($Hypothesis$, $Assumption$, $Outcome$) are all fixed between you and the “competing” researchers. Thus the only term to focus on is your ability to acquire the necessary $Evidence$:
\[\begin{align} P(Evidence) =& P(Evidence | You, Others)\\ =& (1 - P(Evidence | Others))\times P(Evidence | You) \end{align}\]This states that the evidence term depends on you and any other researcher, and that if another researcher gets the evidence before you, then your contribute to evidence drops to $0$. Thus your contribution $P(Evidence|You)$ needs to be weighed by the probability others can’t do the work fast enough.
Given this simple model, it is clear why this is zero sum - your work reduces the impact of others’ impact, and vice versa. As a research community, it signals that there are not enough impactful directions to pursue (e.g., the community is drying up), or that it should prioritize exploratory or “visionary” work. I’ll just note that there as so many important problems in the world that this is unjustified.
Why Research?
Presumably, you are in a research program because you believe doing research is the best way to maximize this probability:
\[E[Impact | You] \propto E[Impact | Your\ Research] + E[Impact | Your\ Nonresearch]\]Clearly there is a strong assumption of the following, based on your desired outcomes:
\[E[Impact | Your\ Research] \gg E[Impact | Your\ Nonresearch]\]For some people, it turns out this assumption is not true, and it is better to leave research and do non-research work. For instance, it can be joining a non-profit, finding an arbitrage opportunity, social entrepreneurship, teaching, etc. All of these are totally totally cool. Remember, opportunities are endless!
Some may try to suggest that you’re not “cut out” for research, implying that $Evidence\rightarrow 0$. Hopefully at this point you would agree that the term is independent of this larger choice.
Unintended Outcomes
Since the goal is to have a positive impact on the world, it is not acceptable to simply state that one is “developing technology for technology’s sake”. This is equivalent to completely ignoring the $Outcome$ or only focusing on positive outcomes. However in reality, we would like to make sure that the positive outcomes far outweigh the negative.
This would seem obvious, but is unfortunately often not the case. In fact, ignoring possible negative outcomes can lead to a crisis of conscience when the negative outcomes become widespread. This is increasingly important as tech integrates closer into our lives and society. This is not unique to researchers. Recently, facebook execs expressed their regret in eroding democracy, while articles about silicon valley make similar statements.
The following is one that’s personally scary to me:
The recent research in automatically generating lipsynced videos is arguably a technology that can have deeply negative consequences. One reason is that it makes it so easy to generate realistic-seeming videos that it fundamentally sheds doubt on what evidence can be believed. The amount of doctored videos can be generated at a higher rate than people can discern and verify them, and subtlely erodes discourse in a way more insidious than simply banning speech.
Following the Crowd
Following the crowd means that the $Assumption\approx 1$. If this is the case, it usually means that many researchers are all aware of the problems to solve, and the desirable outcomes. If this is a rich, unexplored area, then there is no end to the diversity of impactful problems to work on in the area and it is a wonderful opportunity. However, if it is a relatively narrow area that everyone has been working on, then one hopes that your ability to collect $Evidence$ far exceeds others’.
During the 2018 PhD admissions season, seemingly every applicant wants to do deep learning. Why? Because it’s in the news (heavily marketed) and sounds exciting (the set of outcomes is perceived to be high). But if faculty are looking for candidates to help them maximize $Impact$, then how can you, as the applicant, signal that you will be the maximizer? Can you show superior evidence gathering? Or experiment design? Or Vision and Idea generation?
Hammers Without Nails
It is easy to develop systems or techniques by focusing on getting $Hypothesis\times Evidence \approx 1$ (the Hammer). This assumes that the hammer is useful for enough positive outcomes. However, since you’re on the hook looking for positive outcomes (the Nails), it runs the risk of that the intersection between what the paper can improve, and positive outcomes, is null.
Japan has a term for this: Chindōgu (珍道具). Wikipedia says it “is the Japanese art of inventing ingenious everyday gadgets that seem like an ideal solution to a particular problem, but are in fact useless.”
Perfection is the Enemy of Progress
It is often tempting to focus on building the perfect system, getting all possible results, fixing all the bugs, or otherwise writing the perfect paper. This is equivalent to focusing on getting $Evidence = 1$. Based on the model, it is clear that doing so has decreasing marginal benefit unless all other terms are so high that $E[Impact|Paper]$ will actually increase substantially. This seems obvious, but I see it a lot.
Learn more on the wikipedia page
Notice how the impact term basically did not change even as $Evidence\rightarrow 1$. However improving the Assumptions to the same level as the Evidence dramatically improves Impact. It’s simple multiplication.
The desire for perfection can creep up in many ways:
- Not releasing a project because it is not good neough
- Seeking to survey all possible related work before starting
- Editing and re-editing a paper because its writing style is not perfect
- Working on areas where the $Assumptions$ are well established and the $Outcomes$ are nearly as good as they could get: forever polishing a round ball.
A final note: avoiding perfection should not be viewed as discouraging you to strive towards excellence. The former is with respect to an external goal such as a project or paper, whereas the latter is a life-long process of self improvement.
Hard Problems vs Simple Problems
Grad students often prioritize hard problems because it is often viewed as a badge of honor, and shows that you’re smart. A hard problem is a paper where the evidence is basically impossible to get. Solving it supposedly implies that you can solve other hard problems.
Hopefully by this point, it is obvious why problem hardness does not necessarily correlate with high impact, since it says nothing about the other terms (unless the desired outcome is to appear smart). This is why working on simple problems is actually great, as long as it is carefully selected to maximize impact!
Effort
Similar to the previous topic, where working on a hard problem may not necessarily mean impact, putting in an enormous amount of effort is similar. A widely held belief is that effort is correlated with impact, however notice how effort is not explicitly modeled as a key term in our model. It is of value (in our model) if it actually affects our terms.
Instead of debating this point, it’s worth distinguishing two types of effort that differ based on the ends:
- Self improvement: you are the ultimate source of the impact that you will create. Thus, effort devoted towards self-improvement (say, narrowly defined as your ability to maximize any of our model terms) is worth it in the long term, because you will certainly work on multiple projects.
- External improvement: effort for the sake of a paper or project should be consummerate with the impact it is expected to have. A good exercise is to extend our model to take effort (resources) into account as an additional objective term.
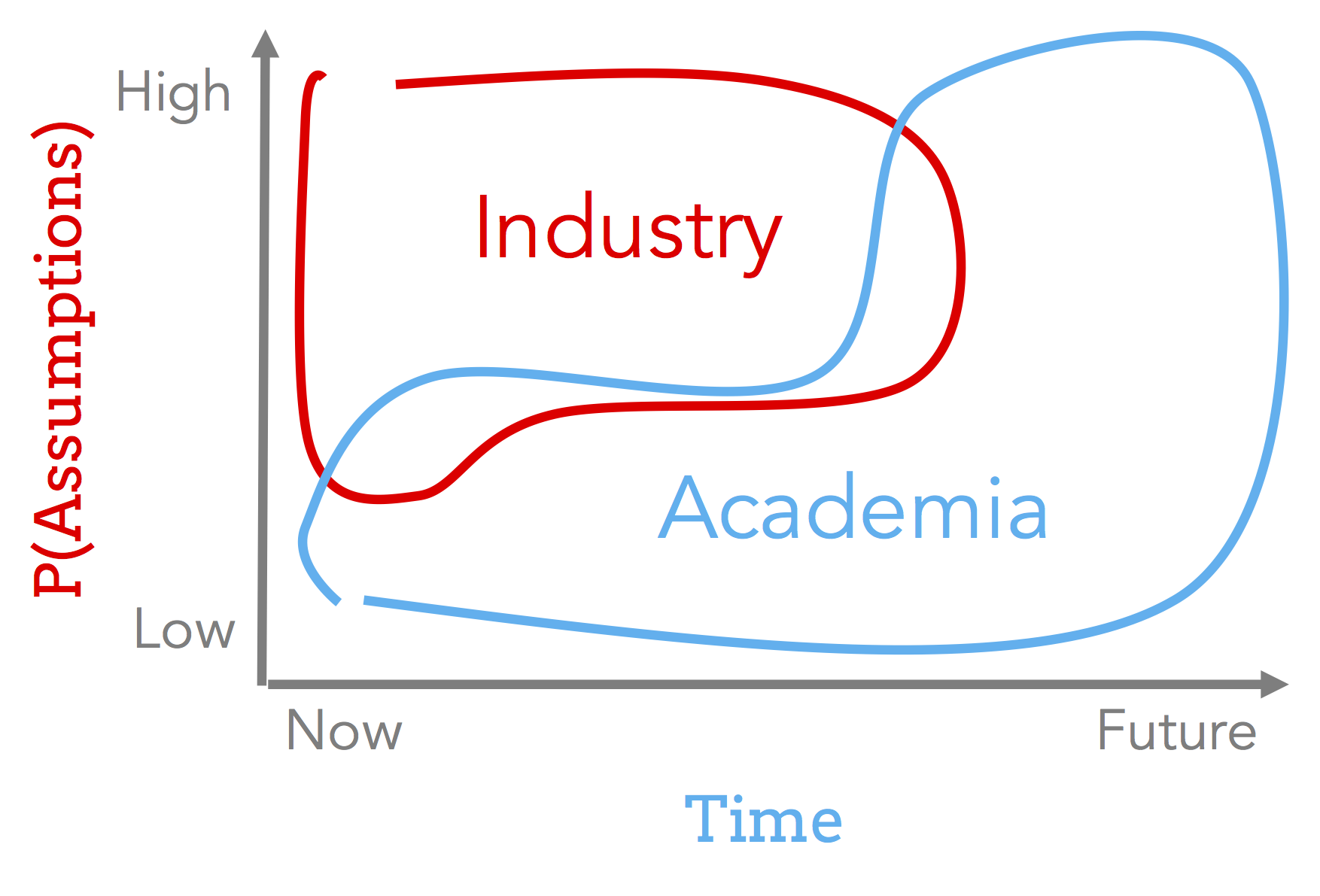
Academia vs Industry
Finally, a comment about doing research in academia vs industry. Arguably, industry has far more resources than academics, so academics should be selective about the class of papers to work on. In other words, we can assume that for the most part, $P(Evidence|Industry)\gg P(Evidence|You)$, however industry has pressure to show short-term results. Thus, the ideal class of problems are ones where $P(Assumption | Now) \approx 0$ and $P(Assumption|Future) \approx 1$. Here’s a made up diagram illustrating the point:
Closing Thoughts
This document argues for modeling the process of research as an optimization problem, and discussed how it can serve as a framework to critically view different facets of the research enterprise. It proposed one possible, and imperfect, model to use as a running example. In my opinion, the most valuable takeaway is the decomposition process from research goals to probabilistic terms, and viewing this through an optimization lens.
If you have ideas of how to improve this document, please submit a pull request or issue, or find me on Twitter.